by Marc Illa
Part of the work is published in this paper on the 11th ISCA Speech Synthesis Workshop.
Dysarthria refers to a group of disorders that typically results from disturbances in the neuromuscular control of speech production and is characterised by a poor articulation of phonemes. In many diseases such as amyotrophic lateral sclerosis (ALS) or Parkinson's, further motor neurons are affected, thus negatively impacting the mobility of the patients and making it difficult for them to initiate and control their muscles movement.
In this thesis, we propose a novel method to synthesise dysarthric speech via non-parallel voice conversion (VC) to: 1) Improve automatic speech recognition (ASR) of people with dysarthria by using synthetic samples as means of data augmentation and 2) Evaluate pathological voice conversion. The motivation for such tasks is: life quality of people with dysarthria could be improved through digital personal assistants with ASR and pathological voice conversion could help inform patients of their pathological speech before commiting to an oral cancer surgery.
Our main contribution is that non-parallel data is used to perform the VC. Parallel data refers to a database containing the same linguistic content for the source and target utterances. This content can be used to train the voice conversion model in a parallel manner. For instance, in an unimpaired to dysarthric speech parallel voice conversion, the unimpaired utterances would be the source and the dysarthric utterances the target. In a non-parallel voice conversion only the target (dysarthric) utterances are needed for training. This is important because dysarthric speech data is scarce and hard to collect.
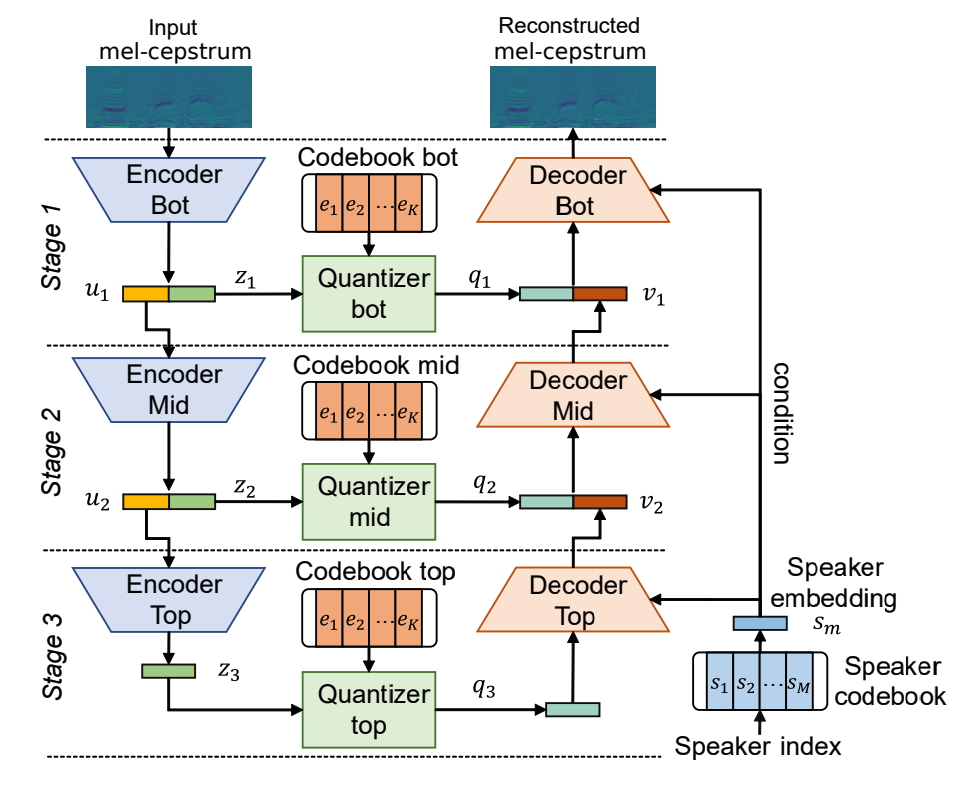
The model is a 3-stage VQ-VAE. It is basically a VAE that encodes discrete codes and has multiple levels. The idea behind this structure is that in the real world a lot of categories are discrete and it makes no sense to interpolate between them (language representations such as words are discrete, speech can be represented with phonemes, images can be categorized...) so discrete representations are intrinsically better for many applications. The mutli-scale structure is useful because on the first levels low-level features are encoded (such as content) and on the higher ones suprasegmental features are encoded (such as emotions).
For voice conversion the model is trained with the mel-cepstrum of the speech from N speakers, and while training, a unique speaker embedding is fed to the decoder together with the discrete latents q. By using the speaker-id to condition the decoder, this one learns to infer the style of each speaker to the encoded speech. Once the model is trained, in a voice conversion scenario, the input to the model is the source speaker speech and the decoder is conditioned with a speaker-id that corresponds to the target speaker. Then, the output of the decoder (the converted mel-cepstrum) can be synthesised to speech with any vocoder that uses Mel-cepstral features. The model is shown in the image below, extracted from (Ho and Akagi, 2020).
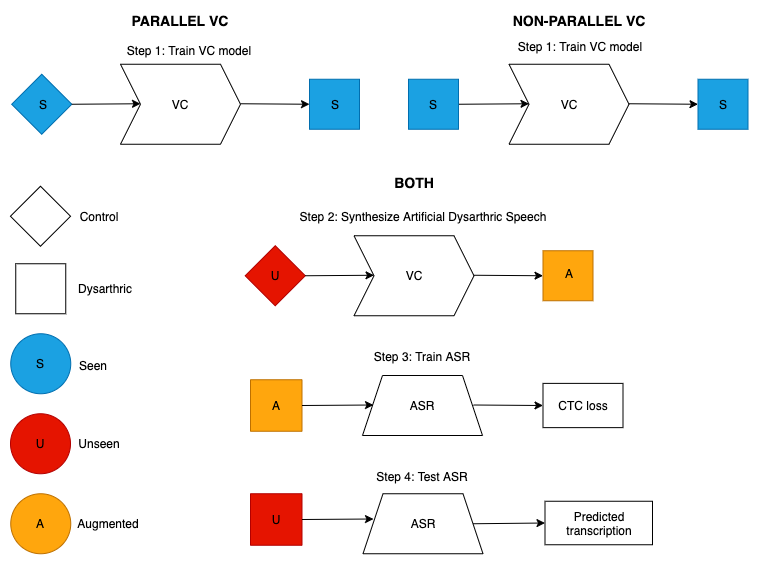
For the first task we reuse the task done by Harvill et al. (2021) where they train an ASR system with dysarthric synthetic data and test it on real dysarthric speech with words that have not been used during training. In order to do that they train a VC model to convert unimpaired to dysarthric speech. Note that in our case the training of the VC model is done with half of the data as it is non-parallel. The corpus used is the UASpeech dataset (Kim et al., 2008). The task workflow is shown on the image below, where diamond shape refers to control speech (unimpaired), and square to dysarthric speech. Blue, red and orange refer to seen, unseen and augmented data respectively as well as the S, U and A letters.
The results for the first task show that for severe speakers, training an ASR system with the synthesised dysarthric speech improves the WER by 4.2 points with respect to training it with unimpaired speech. However, for mild speakers the proposed approach does not improve the results: the WER is 1.0 points higher.
In order to evaluate pathological VC we performed subjective evaluation experiments that were run on the Qualtrics platform, and the participants (10 American English native listeners) were recruited through Prolific. The questionnaire consisted of: a similarity experiment and a naturalness one. The design of the experiments was done following the Voice Conversion Challenge standards.
The results for the second task show that real pathological speech is perceived as less natural than unimpaired speech. As intelligibility decreases, so does the MOS score, showing that naive listeners are not able to separate the severity of the pathology from the naturalness. For mid and low intelligibility speakers the perceived naturalness is close to that of the real samples. For high intelligibility, the results are worse, which is something that also happens in the dysarthric ASR experiments. For the similarity evaluation, the best results are for the low intelligibility speakers where voice characteristics are transferred successfully, for high intelligibility it is also possible to transfer the voice characteristics partially, and for mid intelligibility speakers, the results are inconclusive: we experienced that in one case the VC failed, and on the other, participants fail to recognise the speaker even from the real recordings. Whether the differences in the results for the different intelligibility levels are due to the intelligibility levels or due to other speech characteristics needs to be further investigated.
The thesis provides an insight into non-parallel voice conversion for pathological speakers and its applications. With our contribution, the process of synthesising dysarthric speech is simplified and it becomes more accessible as less data is required. Although there is still a lot of work to be done to adapt voice technologies to pathological speakers, it is encouraging to see that the research field gains traction and more robust systems are built for people with speech impediments.
This is a joint work with the Speech And Language Technologies group of the TU Delft University and the UPC's Machine Translation group. Special mention to Marta R. Costa-jussà, Bence Mark Halpern and Odette Scharenborg for the guidance through the project and to Gerard I. Gállego for collaborating with this blog post.
-
Harvill, J., Issa, D., Hasegawa-Johnson, M., & Yoo, C. (2021). Synthesis of New Words for Improved Dysarthric Speech Recognition on an Expanded Vocabulary. In ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6428-6432).
-
Ho, T. V. & Akagi, M. (2020). Non-parallel Voice Conversion based on Hierarchical Latent Embedding Vector Quantized Variational Autoencoder. In Proc. Joint Workshop for the Blizzard Challenge and Voice Conversion Challenge 2020 (pp. 140–144).
-
Kim, H., Hasegawa-Johnson, M., Perlman, A., Gunderson, J., Huang, T., Watkin, K. L., & Frame, S. (2008). Dysarthric speech database for universal access research. Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, 1741-1744.
@inproceedings{illa21_ssw,
author={Marc Illa and Bence Mark Halpern and Rob van Son and Laureano Moro-Velazquez and Odette Scharenborg},
title={{Pathological voice adaptation with autoencoder-based voice conversion}},
year=2021,
booktitle={Proc. 11th ISCA Speech Synthesis Workshop (SSW 11)},
pages={19--24},
doi={10.21437/SSW.2021-4}
}