by Belén Alastruey
The complete thesis on which this post is based can be found here, and you can also find our paper on arXiv.
The task consisting of translating speech into a written form in another language is popularly known as Speech Translation (ST). It has important applications such as subtitling to another language or translation of non-written languages.
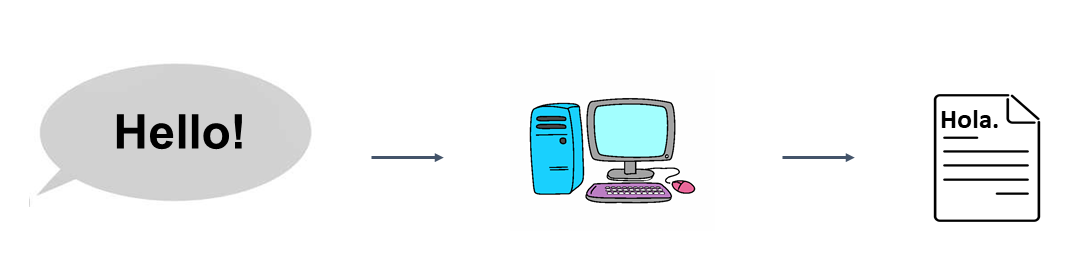
The first ST model consisted of the concatenation of two independent models, forming what nowadays is known as a cascade system (Ney, 1999). The first module, an Automatic Speech Recognition (ASR) model, writes a transcription of the spoken sentence, and the second one, a Machine Translation (MT) model, translates the transcription to another language.

But these models can have a problem. If the ASR algorithm makes a mistake, even with the best MT algorithm we would get a wrong output. For this reason, in the last few years, new models based on end-to-end architectures have emerged. These models are capable of translating from audio to text, without the need to go through the intermediate step of transcription. These models, also known as direct ST systems, have rapidly evolved and, nowadays, they can reach comparable results to cascade models.

Nevertheless, results provided by both cascade and end-to-end architectures are far from optimal, and therefore these research fields are still under development.
The Transformer (Vaswani et al., 2017) is the current state-of-the-art model for text MT. In this model, the attention mechanism evolves from being an enhancement of the algorithm to being its basis. If so far the models used encoder-decoder attention, the Transformer adds a new self-attention mechanism. Self-attention is a mechanism used to determine how much a token is related to the rest of the tokens in the same sentence. This layer allows the model to process the semantics of the input and output sentences. It is placed inside both the encoder and decoder.
But the self-attention layer has quadratic complexity, it requires calculating n^2 attention weights (being n the number of input words), to get one for every possible combination of words in the input sentence.
![]()
This is usually not a problem, but it is if the input is a long sequence, for example in the case of documents. To overcome this problem, many efficient Transformer variants have been proposed, with linear complexity instead of quadratic.
In the last few years, the Transformer has surpassed the barriers of text. In Speech-to-Text context, a standard approach is working with previously extracted audio features. Therefore, input sequence lengths of speech tasks are approximately an order of magnitude longer than usual text sequence lengths. Hence, we must face the same problem as when working with long documents.
A usual approach is using strided convolutions, to reduce the sequence length before the Transformer encoder (Di Gangi et al., 2019; Wang et al., 2020a).
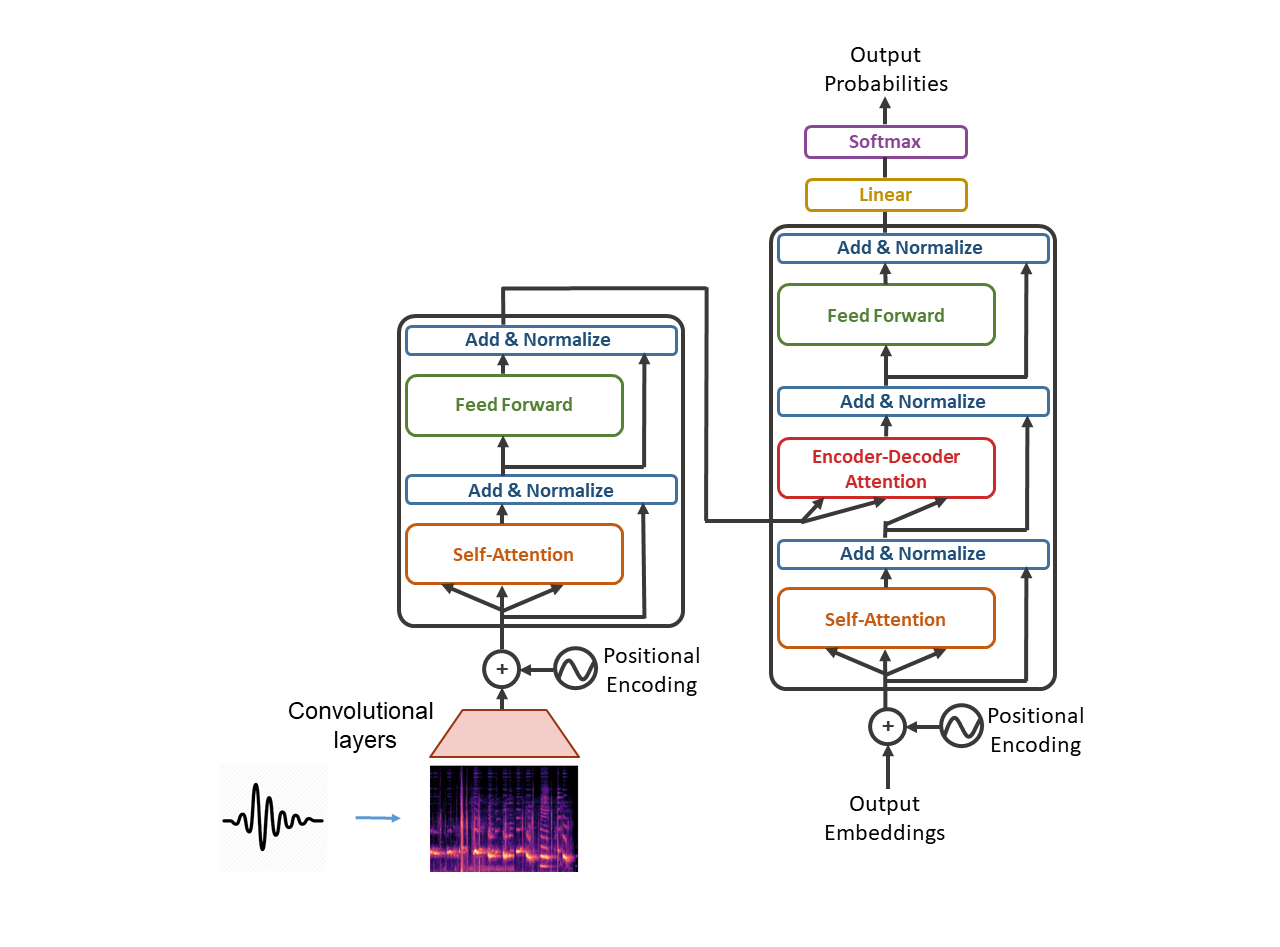
But we believe using this model could have an inconvenience: the Transformer does not have access to the full original input (the mel-spectrogram), but only to the extracted features obtained after the convolutional layers.
Although translating long texts is not the objective of this work, we believe that efficient Transformers could be useful to deal with spoken sentences, since they can help to address the issues caused by long sequences. These models were designed to process long text sequences, which can be extrapolated to speech mel-spectrograms.
Our goal is to take advantage of the lower complexity of these models and create a Speech-to-Text Transformer where the efficient Transformer deals with the audio input. To achieve this, we propose an architecture where the self-attention layer in a Transformer encoder is substituted by an efficient one. We believe the training could benefit from this approach, since it lets the model learn directly from the spectrogram and no information is lost in the convolutional layers.
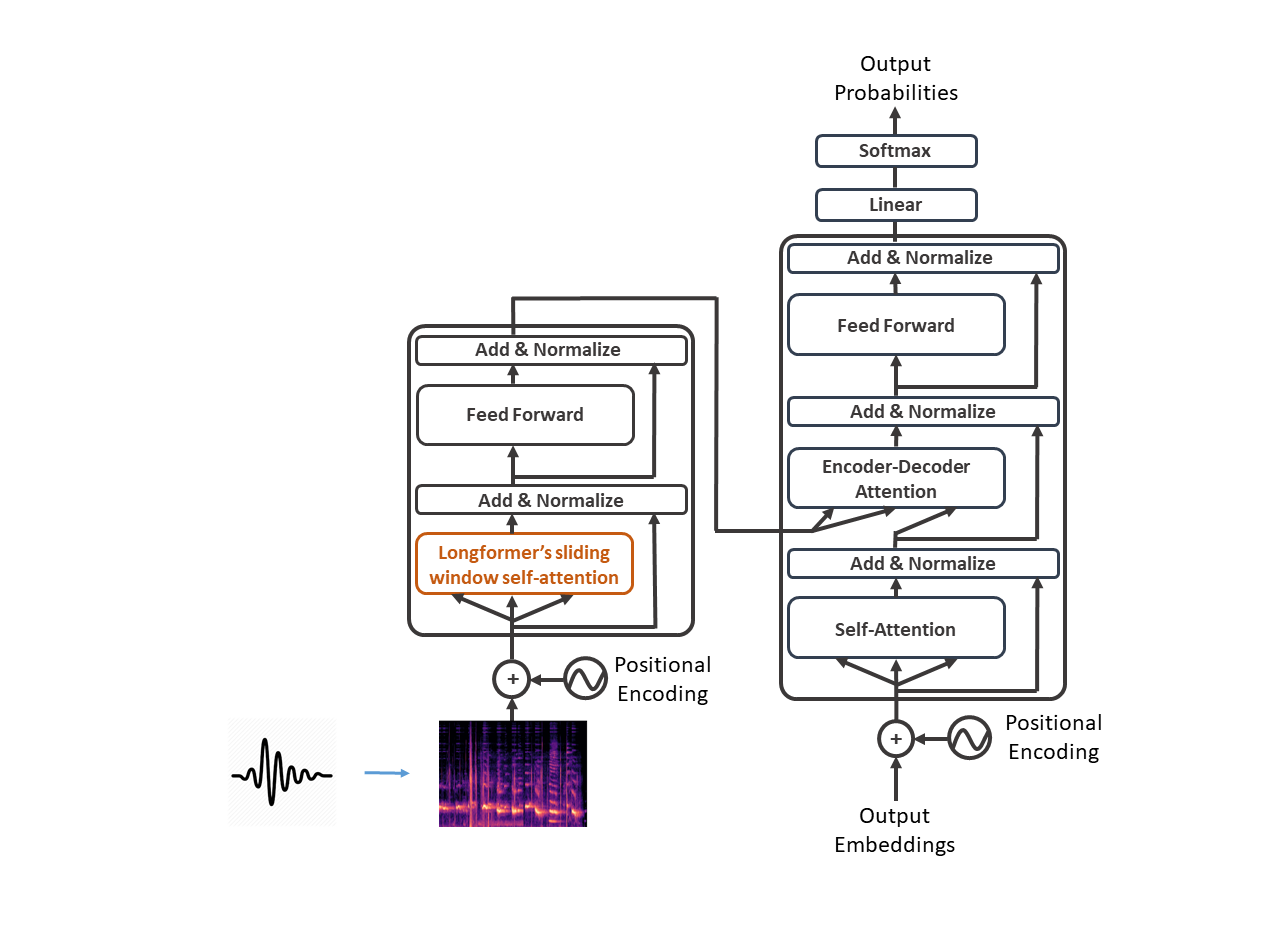
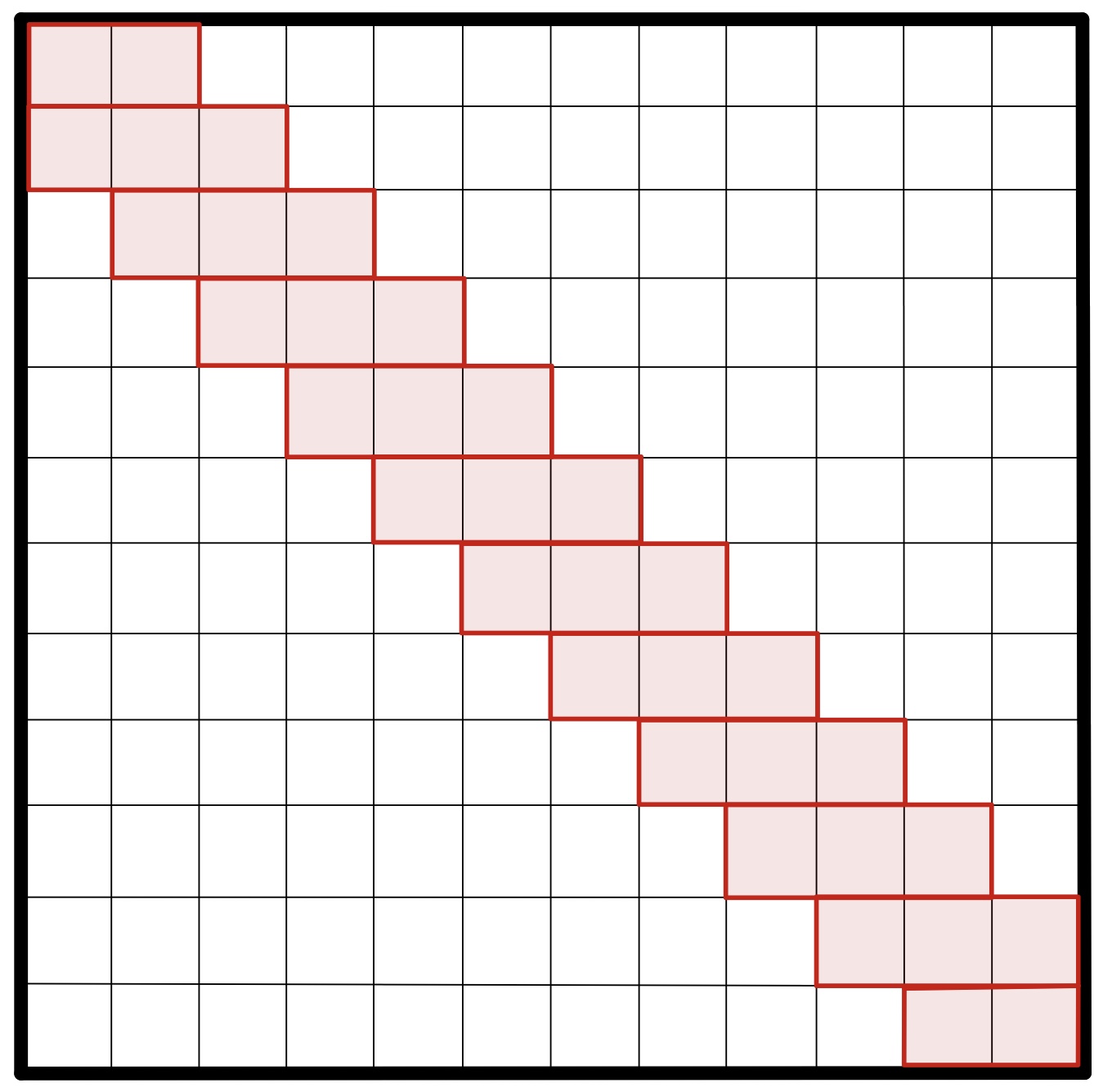
After considering different efficient Transformer models, we chose the Longformer (Beltagy et al., 2020) for our first experiments. The Longformer is a variation on the original Transformer, which achieves a reduction in the complexity of the attention computation, from quadratic to linear. To achieve this, the Longformer defines a pattern in the attention matrix, specifying, for each token combination, the attention weights that need to be computed. Longformer's attention pattern is mainly based on a sliding window, it relies on the importance of local context. An attention window of fixed size is placed around each token.
We performed experiments on ASR and ST using our proposed Speech-to-Text Longformer (s2t_longformer) architecture: a Longformer encoder and a regular Transformer decoder.
We compared our systems with the Speech-to-Text Transformer (s2t_transformer) model available in Fairseq (Wang et al., 2020a), to evaluate the performance of our systems regarding a baseline.
We trained these models on the MUST-C dataset, and we obtained the following results:
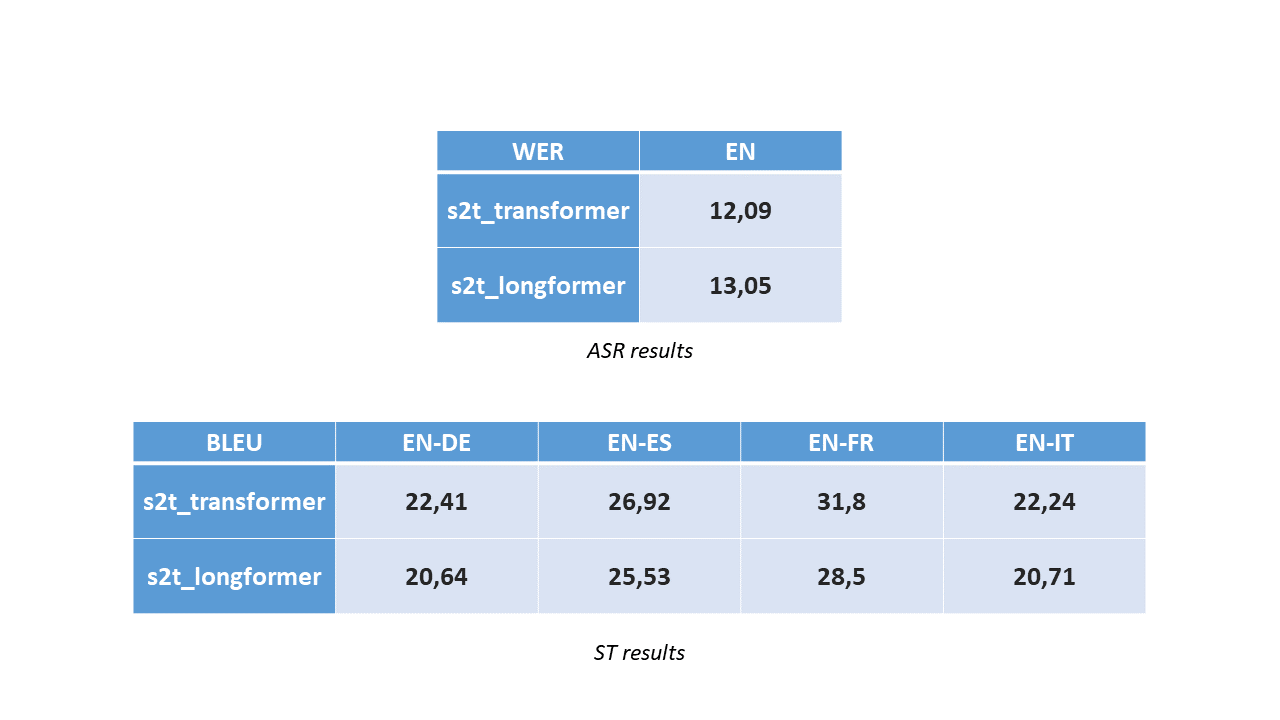
As you can see, our results are close to the ones obtained with convolutional layers and a regular Transformer, showing less than a 10% relative reduction of the performance, meaning that this is a great starting point for a promising research path.
Finally, in future work, we could try other efficient Transformers, such as the Linformer (Wang et al., 2020b), an encoder-based model with linear complexity, that therefore could be suitable for a model like ours.
This is joint work with Gerard I. Gállego and Marta R. Costa-jussà. I would like to thank UPC's Machine Translation group, and especially them both, for letting me work on this project and for their help and support.
- Beltagy, I., Peters, M., & Cohan, A. (2020). Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150.
- Di Gangi, M., Negri, M., & Turchi, M. (2019). Adapting transformer to end-to-end spoken language translation. In INTERSPEECH 2019 (pp. 1133–1137).
- Ney, H. (1999). Speech translation: coupling of recognition and translation. In 1999 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings. ICASSP99 (Cat. No.99CH36258) (pp. 517-520 vol.1).
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A., Kaiser, ., & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998–6008).
- Wang, C., Tang, Y., Ma, X., Wu, A., Okhonko, D., & Pino, J. (2020a). Fairseq S2T: Fast Speech-to-Text Modeling with Fairseq. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations (pp. 33–39).
- Wang, S., Li, B., Khabsa, M., Fang, H., & Ma, H. (2020b). Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768.
@article{thesis_alastruey_2021,
title={Efficient Transformer for Direct Speech Translation},
author={Belen Alastruey and Gerard I. G{\'a}llego and M. Costa-juss{\`a}},
journal={ArXiv},
volume={abs/2107.03069},
}