by Lluís Guardia
Right now, one of the main problems in the field of machine translation is that models are trained once, and they remain static over time.
The typical problem case example follows the following steps: First, we have a model trained in 2008, to say any year, which does a great job at it, but as time passes and new contexts appear, also new words appear such as Bitcoins, which almost no one heard before 2020. In this case, the model doesn’t understand this new word and comes up with an incorrect translation. To solve this problem, the models have to be trained again from scratch with data up to date to be able to output an accurate result.

In this research, we tried to address this problem by developing and evaluating the usage of Quality Estimation by active learning as a lifelong learning technique. This is for a system that adapts to data that is evolving over time without having the train to model from scratch again.
To develop and evaluate the lifelong learning system, we needed a structure that allows us to do so. We used the structure given by the LLMT task at the WMT21 conference.
But before explaining the system, we have to take a little detour at the data. For it we used English-to-French and English-to-German tasks.
We divided the data used on the system into two: first, the training data consists of a set of documents provided on the WMT tasks between 1996 and 2013 (Europarl and NewsCommentary datasets) on the corresponding years and also contain the complete translations of all the documents to the target language.
On the other hand, the lifelong data consists of the same documents as in training, but between the years 2014 to 2020. The difference, in this case, is that this data also contains the translation, but we are not using them, the lifelong data only contains the source sentences.
Now we can talk about the system. This system, as represented in the figure, receives the previously explained data and preprocess it. The preprocessed training data is used to train an initial translation model. This model will try to translate the preprocessed lifelong data and use this same data to improve and learn more using active learning methods.

Additionally, externally to the system, there is a user that can interact with the lifelong learning module, providing the translation for the sentences queried by the system. In our case though, this is an automated block that returns the translation automatically, this translation consists of the target language sentence discarded previously (as commented in DATA). It has to be noted that this process, in reality, involves a notorious increase in the processing time, and so it has been considered the number of times that the human help has been requested with a penalization on the evaluation score.
The intention is that the lifelong module asks for the translation of some sentences that will be used to train the lifelong model previously to the document translation and improve and obtain the best possible output results.
Finally, the system performance is evaluated by an evaluation block that takes the translations of the lifelong data and implements a score formed by the score obtained by the system and two other values which form the penalization score.
We decided that 10% of the sentences in the document will be sent to the user translation block. Using Quality Estimation, we developed a strategy to select which sentences would be the most useful when sent to the user translation block.
With Quality Estimation, we train a model using the Openkiwi framework and the model tries to predict how good the machine translations are for each sentence, giving as result an HTER score. This HTER score indicates the minimum number of edits on the output sentence required to capture the complete meaning of the reference sentence. We used HTER instead of BLEU in this implementation because, as presented by Snover et al. (2006), HTER has a better correlation with the human judgement of fidelity and fluidity. Once the model has predicted the scores for the document, the weakest sentences will be the ones we sent to the user translation block.
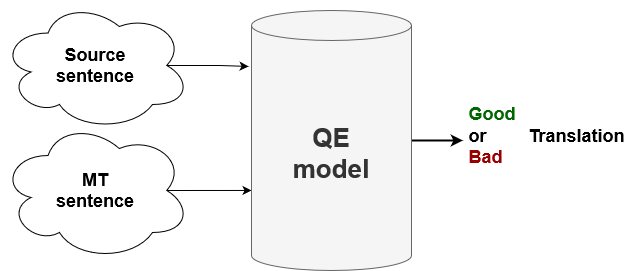
In our case we trained various predictor-estimator models, with different input configurations and different parameters values searching for combinations with better results.
As the results, first we evaluated the results obtained with the different QualityEstimation models using Pearson and Spearman correlations as the evaluation scores, with them, we measure the linear and rank correlation, respectively, between the results obtained and the results expected.
From all of those results, we selected two models for each pair of languages, implemented them into the lifelong block, and obtained the system results using those. Additionally, as a baseline, we implemented a random sampling method to compare them.

We can observe how the results obtained with the Quality Estimation models outscore the random ones. Also, when looking at the results obtained with Quality Estimation, there are indications that there is some correlation between the system results and the Quality Estimation model performance.
In this research, we have shown that the usage of Quality Estimation models improves the results obtained on lifelong learning systems With this, we expect that more researchers will see that lifelong learning is also feasible in machine translation.
This is joint work with Magdalena Biesialska and Marta R. Costa-jussà. I would like to thank them both, along with the UPC's Machine Translation group, for guiding and helping me through this project.
@misc{thesis_guardia_2021,
title={Exploring Lifelong Learning in Neural Machine Translation},
author={Guardia, Lluís},
year={2021},
}