by Magdalena Biesialska
In this post, we present a set of seminal works on lifelong learning that have shaped the field and allowed deep learning methods to learn without forgetting.
Humans learn and accumulate knowledge and skills throughout their lifetime (e.g. Ruiz Martín, 2020). For some years now scholars have been trying to transfer this idea into the realm of artificial intelligence. This area of research is termed lifelong learning (LLL), but other names like: continual learning, incremental learning, sequential learning, or never-ending learning are often used interchangeably.
LLL aims to enable information systems to learn from a continuous stream of data across time. In result, deployed systems could adapt in a continuous manner even if task or domain changes. However, this scenario is very challenging as the general limitations of machine learning methods apply to neural network-based models. Contemporary neural networks learn in isolation, and are not able to effectively learn new information without forgetting previously acquired knowledge. This phenomenon is called catastrophic forgetting (McCloskey and Cohen, 1989).
In this post, we will focus on the methods that have a great impact and allow to apply the LLL paradigm in deep learning models. However, other important considerations, regarding: datasets, evaluation methods and benchmarks among others, are outside the scope of this article.

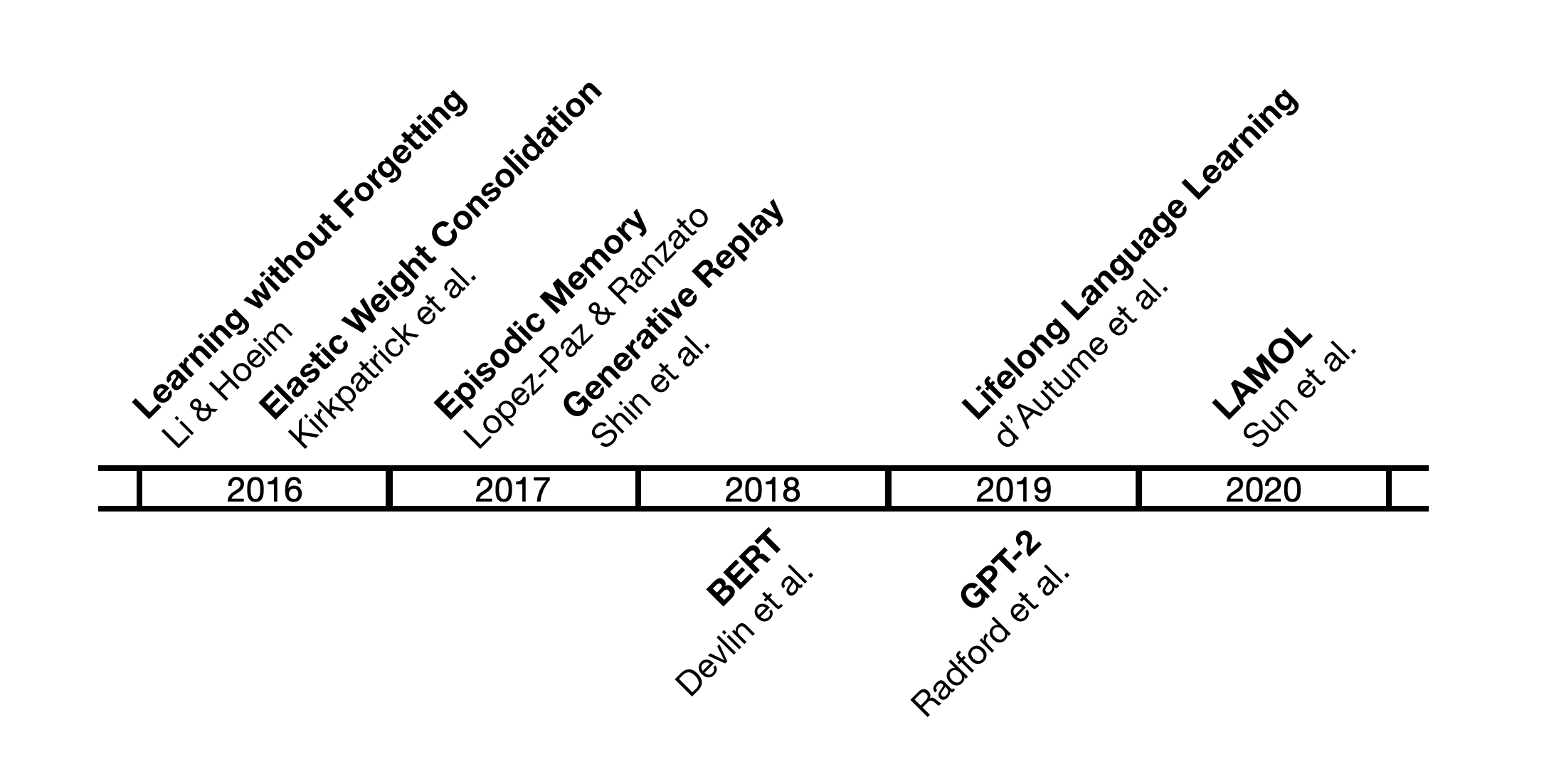
One of the first works on LLL for deep learning was published by Li & Hoiem (2016). The authors use convolutional neural networks (CNNs) on various image classification tasks. Their approach, dubbed Learning without Forgetting (LwF), relies on the distillation loss (Hinton et al., 2015) to keep knowledge of previous tasks. While previously learned knowledge is distilled to preserve the performance on old tasks and enable learning of a new task, access to prior training data is not required. In other words, the goal is to learn model parameters that work well on old and new tasks using only examples from the new task.
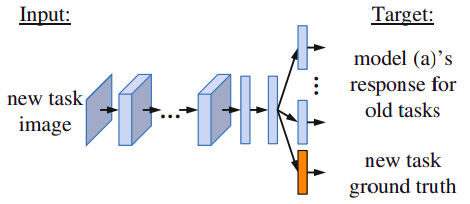
More specifically, first the model freezes the parameters of old tasks and trains solely the new ones. Afterwards, all network parameters are trained jointly. This way the network is trained to minimize the loss for all tasks. However, unless new tasks feed the network with data similar to previous tasks, LwF is prone to degrade model's performance on old tasks.

Similar to LwF, Elastic Weight Consolidation (EWC; Kirkpatrick et al., 2016) is also considered a regularization method. The authors test their approach on reinforcement learning problems. Unlike LwF, where knowledge distillation is used to prevent catastrophic forgetting, EWC uses quadratic penalty to constraint important network weights of previous tasks to remain close to their old values.
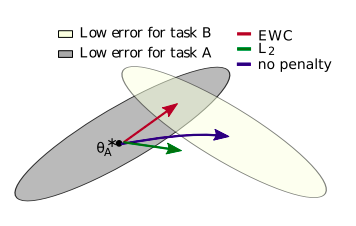
As it can be seen in the figure above, EWC ensures that the performance on task A is preserved and the model learns task B by taking gradient steps according to the red arrow. In this case, each weight is evaluated on the importance of it with respect to task A. Neither blue arrow (loss is minimized for task B) nor green one (task B is not learned because each weight is constrained with the same penalty) satisfy this condition. Essentially, each weight is pulled back towards its old value by an amount proportional to its contribution to the performance on previous tasks.

Memory methods such as Gradient Episodic Memory (GEM; Lopez-Paz and Ranzato, 2017) and its improved variant A-GEM (Chaudhry et al., 2019) use an episodic memory to alleviate catastrophic forgetting by storing some amount of data from previous tasks. In GEM old data is used as a constraint to optimize the model. The authors compare their methods against other LLL approaches (e.g. EWC) and conclude that GEM and A-GEM demonstrate better performance while having lower computational requirements.
Another important aspect of the work of Lopez-Paz and Ranzato (2017) is related to the LLL setting and how methods should be tested in such conditions. The authors define three metrics, which aim to characterize and help to evaluate models on their ability to transfer knowledge across tasks.
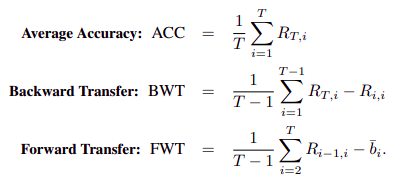
While accuracy is a standard metric that is used to evaluate models irrespective of the setting, backward transfer and forward transfer are specific to cases where transfer of knowledge is required. The former measures the impact that learning a new task has on the performance of a previous task. While, the latter evaluates the influence that learning a new task has on the performance of a future task. In general, the higher the values of these metrics, the better the quality of the model.

The work of Shin et al. (2017) introduces generative replay (GR) as an alternative for storing data from old tasks. The model keeps previously learned knowledge thanks to the replay of generated pseudo-samples.
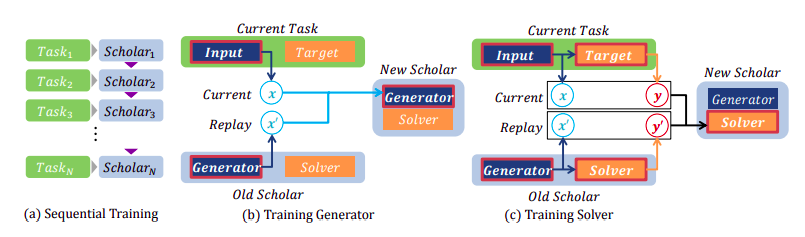
In order to generate data that resembles previously seen examples, the authors use generative adversarial networks. Next, such generated data are paired together with corresponding predictions from the past task solver to represent old tasks. The generator-solver pair, called scholar, produces fake data as well as target pairs. When a new task is introduced these produced pairs are mixed with new data to update both the generator and solver networks. In consequence, a scholar model can learn the new task without suffering from catastrophic forgetting as well as teach other models with generated input-target pairs. Although the GR method shows good results, it leverages generative adversarial networks which are notoriously difficult to train.

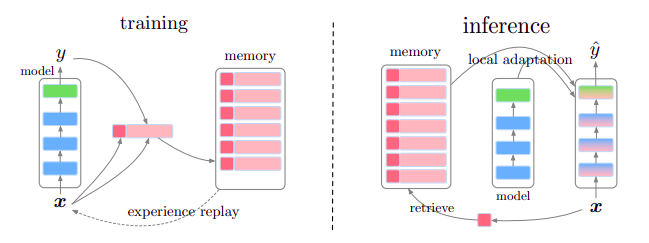
In the context of NLP, LM-based methods for LLL have been recently proposed. d’Autume et al. (2019) introduced MbPA++ model that is based on the encoder-decoder architecture augmented with an episodic memory module. By using this module for sparse experience replay and local adaptation, the authors aim to alleviate catastrophic forgetting and increase positive transfer. In the training phase, new task examples are used to update the base model and are stored in the memory. From time to time, experience replay using the samples from the memory is used to update the base model.
Another method, LAnguage MOdeling for Lifelong language learning (LAMOL), was proposed by Sun et al. (2020). Their approach is based on language modeling as well, however, the authors use a GPT-2 model (Radford et al., 2019) instead of BERT (Devlin et al., 2019) that is utilized by MbPA++. Moreover, unlike MbPA++, this method does not require any additional memory module. LAMOL mitigates catastrophic forgetting by generating pseudo-samples of old tasks to be replayed along with new task data.
LLL is a very broad and active research area. In this blog post, we shed light on the influential LLL approaches that have been serving as an inspiration to many later works. While most of these methods have originated from computer vision and reinforcement learning, we also wanted to show how LLL approaches can be used in the NLP field. Given the format and limited length of the blog post, we refer the readers to the publications of Chen & Liu (2018) and Biesialska et al. (2020) for a comprehensive review of LLL in NLP.
-
Magdalena Biesialska, Katarzyna Biesialska, and Marta R. Costa-jussà. 2020. Continual Lifelong Learning in Natural Language Processing: A Survey. In International Conference on Computational Linguistics (COLING), pages 6523–6541.
-
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. 2019. Efficient lifelong learning with A-GEM. In International Conference on Learning Representations (ICLR).
-
Zhiyuan Chen and Bing Liu. 2018. Lifelong machine learning. Synthesis Lectures on Artificial Intelligence and Machine Learning, 12(3):1–207.
-
Cyprien de Masson d’Autume, Sebastian Ruder, Lingpeng Kong, and Dani Yogatama. 2019. Episodic memory in lifelong language learning. In Advances in Neural Information Processing Systems (NeurIPS), pages 13143–13152.
-
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), pages 4171–4186.
-
Geoffrey E. Hinton, Oriol Vinyals and J. Dean. Distilling the Knowledge in a Neural Network. 2015. ArXiv abs/1503.02531
-
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwińska, et al. 2016. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences of the United States of America, 114(13):3521.
-
Zhizhong Li and Derek Hoiem. 2016. Learning without forgetting. In European Conference on Computer Vision (ECCV), pages 614–629. Springer.
-
David Lopez-Paz and Marc’Aurelio Ranzato. 2017. Gradient episodic memory for continual learning. In Advances in Neural Information Processing Systems (NeurIPS), pages 6467–6476.
-
Michael McCloskey and Neal J Cohen. 1989. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of learning and motivation, volume 24, pages 109–165. Elsevier.
-
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI Blog.
-
Héctor Ruiz Martín. 2020. ¿Cómo aprendemos?: una aproximación científica al aprendizaje y la enseñanza. Editorial Graó.
-
Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. 2017. Continual learning with deep generative replay. In Advances in Neural Information Processing Systems (NeurIPS), pages 2990–2999.
-
Fan-Keng Sun, Cheng-Hao Ho, and Hung-Yi Lee. 2020. LAMOL: LAnguage MOdeling for Lifelong Language Learning. In International Conference on Learning Representations (ICLR).
@misc{biesialska-major-breakthroughs-lifelonglearning,
author = {Biesialska, Magdalena},
title = {Major Breakthroughs in... Lifelong Learning (VIII)},
year = {2021},
howpublished = {\url{https://mt.cs.upc.edu/2021/04/12/major-breakthroughs-in-lifelong-learning-viii/}},
}