by Magdalena Biesialska
In this post, we continue our exciting journey of discussing various research lines across the Machine Translation (MT) field. Here we focus on unsupervised approaches to MT that have emerged only recently.
The majority of current NMT systems is still trained using large bilingual corpora, which are available only for a handful of domains and high-resource language pairs. This is mainly caused by the fact that creating parallel corpora requires a great amount of resources (e.g. data, knowledge, time, money). In result, such datasets are costly to produce, and thus access to them is often expensive as well.
While parallel corpora are still scarce, in any language there is an abundance of monolingual data that is freely available. Especially, access to in-domain monolingual textual data – even for low-resource languages – is far easier than for parallel corpora. Therefore, research on unsupervised MT focuses on eliminating the dependency on labeled data, which is especially beneficial for low-resource languages.
Cross-lingual embeddings (CLEs) allow to learn multilingual word representations. CLEs are important components that facilitate cross-lingual transfer in current NLP models and proved to be very useful in downstream NLP tasks (such as MT). Importantly, CLEs help to bridge the gap between resource-rich and low-resource languages, because CLEs can be trained even without using any parallel corpora, as we will see below.
Let us discuss now the most prominent CLE methods. In principle, vector spaces representing words in different languages can be aligned, because words with similar meanings have similar statistical properties regardless of the language. Many current CLE methods map two monolingual distributions of words to a shared vector space using linear transformations.
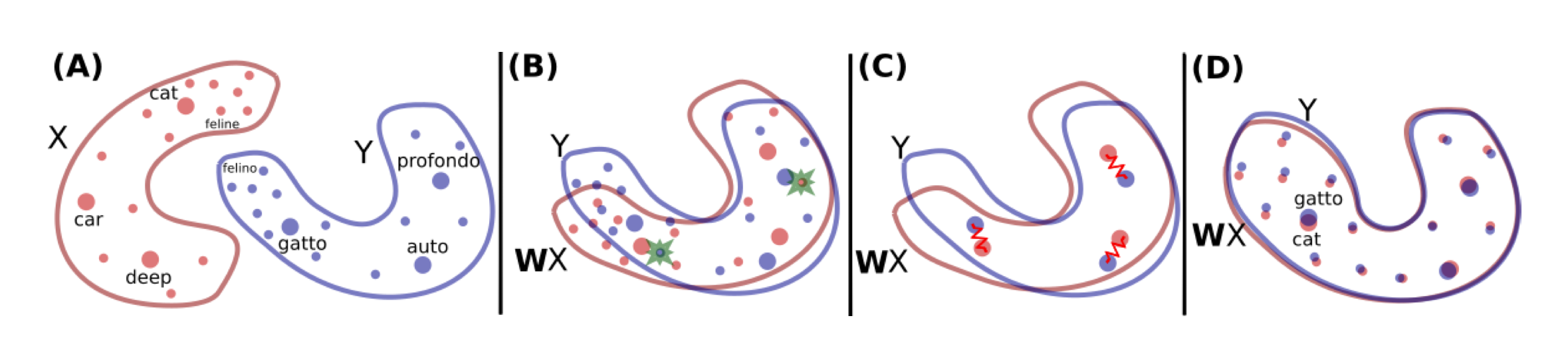
For a long time mapping techniques have required supervision (e.g. Klementiev et al., 2012; Mikolov et al., 2013); however, now the state-of-the-art methods VecMap (Artetxe et al., 2017, 2018b) and MUSE (Lample et al., 2018a) allow to learn the alignment with a very small seed lexicon or even without parallel data at all.

As illustrated in the figure above (Lample et al., 2018a), the English word distribution (X) is aligned with the Italian word distribution (Y) using simply a translation matrix (W). The mapping (W) is refined using the orthogonal procrustes method. It is worth mentioning that Xing et al. (2015) report that translations can be substantially improved by imposing an orthogonality constraint on W. While in the unsupervised variant of CLE, Zhang et al. (2017) and Lample et al. (2018a) utilize an adversarial criterion, Artetxe et al. (2017, 2018b) rely on a multi-step linear transformation framework.
Given that the quality of pre-trained cross-lingual word embeddings has a significant impact on the performance of downstream NLP tasks, several methods for refining cross-lingual embeddings have been proposed (e.g. Doval et al., 2018; Zhang et al., 2019; Biesialska & Costa-jussà, 2020).
Motivated by recent successful attempts to unsupervised CLEs, the natural next step was to try to build NMT systems without any form of supervision. Unsupervised NMT (UNMT) aims to train a neural translation model only with monolingual data, which is considered a more challenging scenario as compared to a traditional supervised MT setting.

In the early 2018 two novel UNMT models were introduced by Artetxe et al. (2018a) and Lample et al. (2018b). In general, we can distinguish three elements that are common to these approaches. First, using CLE methods monolingual source and target embeddings are mapped into a cross-lingual vector space. These CLEs are then used to initialize the encoder and decoder of a UNMT model. Both Artetxe et al. (2018a) and Lample et al. (2018b) employ a single encoder; however, the latter UNMT model is built with a shared decoder, while the former uses language-specific decoders. Thanks to pre-trained CLEs, a shared encoder is able to generate language-independent representation of the input sentence.
Afterwards the UNMT system is trained using a combination of (i) denoising auto-encoding and (ii) iterative back-translation. The denoising auto-encoding objective is used to improve learning ability of the model with respect to language-specific properties (e.g. word order). This is achieved by corrupting the input sentence and reconstructing it with the decoder in the same language. While the iterative back-translation, which is crucial to attain good performance, is based on the same principles as the standard variant described in one of our previous posts.
Other notable approaches to UNMT were introduced in the works of Yang et al. (2018), Sun et al. (2019) and Sen et al. (2019).
Alternative approaches, which leverage phrase-based Statistical Machine Translation (SMT), have been also proposed (Artetxe et al., 2018c; Lample et al., 2018c; Artetxe et al., 2019, Ren et al., 2019). Employing SMT models has provided improvements over the previous state-of-the-art in UNMT.

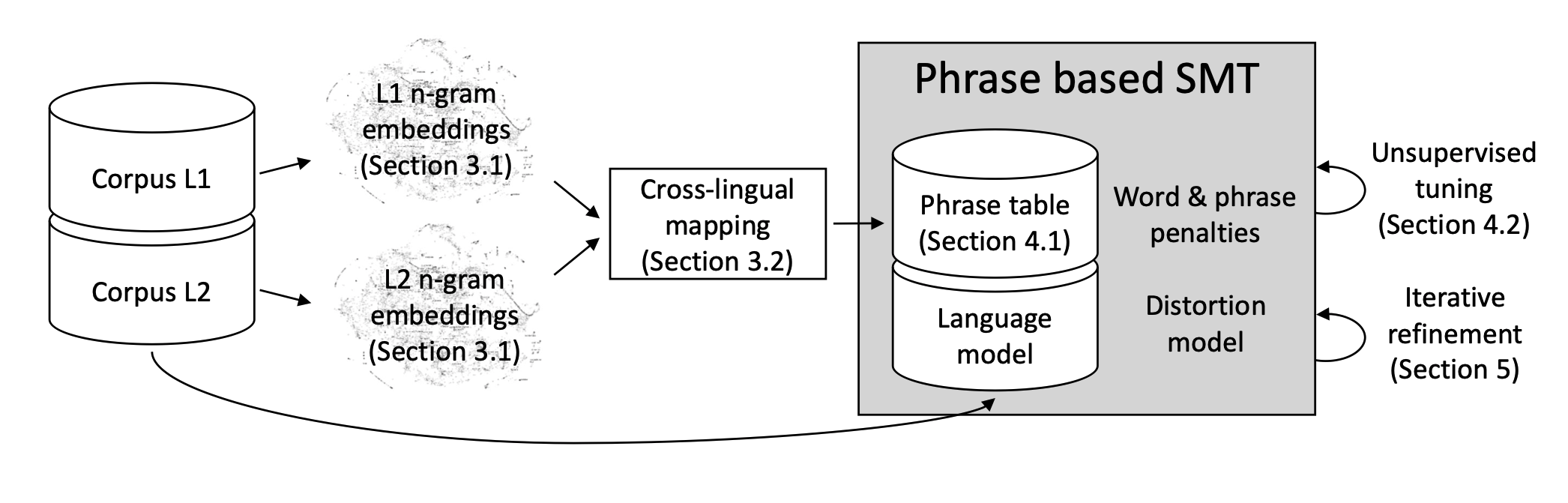
As depicted in the figure above (Artetxe et al., 2018c), unsupervised SMT models initialize a phrase-table with cross-lingual n-gram embeddings. This works in a combination with n-gram language model and a distortion model. Such a system makes use of iterative back-translation and joint refinement. SMTs are better at dealing with noisy data, thanks to this UNMT models are less susceptible to random errors and noise introduced with synthetic parallel corpora during training.

Lately, building upon language modeling pre-training methods such as BERT (Devlin et al., 2018), Conneau and Lample (2019) have introduced cross-lingual language modeling (XLM) approach. Unlike previous attempts, where cross-lingual embeddings were used to initialize the lookup table, they propose to pre-train the full model (encoder and decoder) with a cross-lingual language model (LM), showing significant performance gains in UNMT.
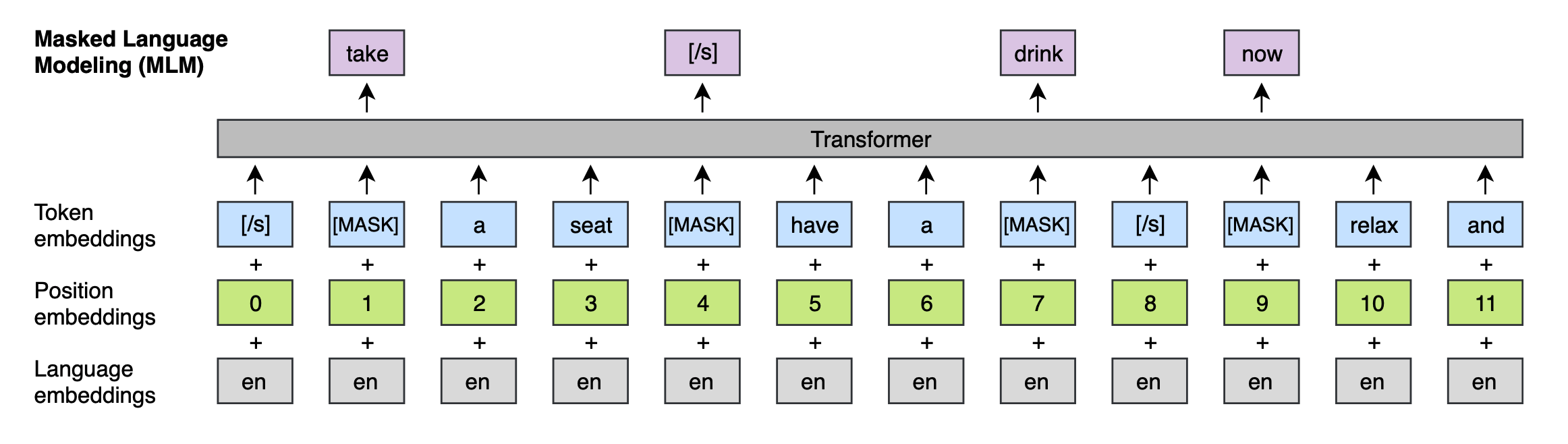
In order to adapt BERT architecture to a UNMT setting, XLM is trained on the concatenation of monolingual corpora. In contrast to the unsupervised NMT and SMT based approaches, the model's encoder and decoder are both initialized with the same pre-trained cross-lingual LM. However, in XLM the encoder and decoder are not pre-trained jointly, which is suboptimal for the NMT task. This problem is addressed in the MASS architecture introduced by Song et al. (2019).
Most recently, new models such as BART (and its multilingual variant mBART) have been proposed (Lewis et al., 2020). BART is based on a typical encoder-decoder architecture, where the bidirectional encoder can be seen as a generalization of BERT, while the autoregressive decoder resembles the GPT (Radford et al., 2018) architecture. Moreover, BART introduces several noising strategies, which aim to make the model more robust and improve generalization.
Unsupervised NMT is a challenging scenario, however it may allow to overcome some of the most pressing problems related to MT for low-resource languages. Although the field of UNMT is fairly new, it has been evolving rapidly. Current UNMT models achieve results that are promising, yet we think that the performance of UNMT can be further improved with a better initialization.
-
Artetxe, M., Labaka, G., & Agirre, E. (2017). Learning bilingual word embeddings with (almost) no bilingual data. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 451–462). Association for Computational Linguistics.
-
Artetxe, M., Labaka, G., Agirre, E., & Cho, K. (2018a). Unsupervised neural machine translation. In 6th International Conference on Learning Representations, ICLR 2018.
-
Artetxe, M., Labaka, G., & Agirre, E. (2018b). A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 789–798). Association for Computational Linguistics.
-
Artetxe, M., Labaka, G., & Agirre, E. (2018c). Unsupervised Statistical Machine Translation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (pp. 3632–3642). Association for Computational Linguistics.
-
Artetxe, M., Labaka, G., & Agirre, E. (2019). An Effective Approach to Unsupervised Machine Translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 194–203). Association for Computational Linguistics.
-
Biesialska, M., & Costa-jussà, M. (2020). Refinement of Unsupervised Cross-Lingual Word Embeddings. In ECAI 2020 - 24th European Conference on Artificial Intelligence (pp. 1978–1981). IOS Press.
-
Conneau, A., & Lample, G. (2019). Cross-lingual Language Model Pretraining. In Advances in Neural Information Processing Systems. Curran Associates, Inc.
-
Devlin, J., Chang, M.W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (pp. 4171–4186). Association for Computational Linguistics.
-
Doval, Y., Camacho-Collados, J., Espinosa-Anke, L., & Schockaert, S. (2018). Improving Cross-Lingual Word Embeddings by Meeting in the Middle. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (pp. 294–304). Association for Computational Linguistics.
-
Klementiev, A., Titov, I., & Bhattarai, B. (2012). Inducing Crosslingual Distributed Representations of Words. In Proceedings of COLING 2012 (pp. 1459–1474). The COLING 2012 Organizing Committee.
-
Lample, G., Conneau, A., Ranzato, M. A., Denoyer, L., & Jégou, H. (2018a). Word translation without parallel data. In International Conference on Learning Representations.
-
Lample, G., Conneau, A., Denoyer, L., & Ranzato, M. (2018b). Unsupervised Machine Translation Using Monolingual Corpora Only. In 6th International Conference on Learning Representations, ICLR 2018.
-
Lample, G., Ott, M., Conneau, A., Denoyer, L., & Ranzato, M. (2018c). Phrase-Based & Neural Unsupervised Machine Translation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (pp. 5039–5049). Association for Computational Linguistics.
-
Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., Stoyanov, V., & Zettlemoyer, L. (2020). BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (pp. 7871–7880). Association for Computational Linguistics.
-
Mikolov, T., Le, Q. V., & Sutskever, I. (2013). Exploiting similarities among languages for machine translation. arXiv preprint arXiv:1309.4168.
-
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
-
Ren, S., Zhang, Z., Liu, S., Zhou, M., & Ma, S. (2019). Unsupervised Neural Machine Translation with SMT as Posterior Regularization. Proceedings of the AAAI Conference on Artificial Intelligence, 33(01), 241-248.
-
Sen, S., Gupta, K., Ekbal, A., & Bhattacharyya, P. (2019). Multilingual Unsupervised NMT using Shared Encoder and Language-Specific Decoders. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 3083–3089). Association for Computational Linguistics.
-
Song, K., Tan, X., Qin, T., Lu, J., & Liu, T.Y. (2019). MASS: Masked Sequence to Sequence Pre-training for Language Generation. In International Conference on Machine Learning (pp. 5926–5936).
-
Sun, H., Wang, R., Chen, K., Utiyama, M., Sumita, E., & Zhao, T. (2019). Unsupervised Bilingual Word Embedding Agreement for Unsupervised Neural Machine Translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 1235–1245). Association for Computational Linguistics.
-
Xing, C., Wang, D., Liu, C., & Lin, Y. (2015). Normalized Word Embedding and Orthogonal Transform for Bilingual Word Translation. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 1006–1011). Association for Computational Linguistics.
-
Yang, Z., Chen, W., Wang, F., & Xu, B. (2018). Unsupervised Neural Machine Translation with Weight Sharing. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 46–55). Association for Computational Linguistics.
-
Zhang, M., Liu, Y., Luan, H., & Sun, M. (2017). Adversarial Training for Unsupervised Bilingual Lexicon Induction. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 1959–1970). Association for Computational Linguistics.
-
Zhang, M., Xu, K., Kawarabayashi, K.i., Jegelka, S., & Boyd-Graber, J. (2019). Are Girls Neko or Shōjo? Cross-Lingual Alignment of Non-Isomorphic Embeddings with Iterative Normalization. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 3180–3189). Association for Computational Linguistics.
@misc{biesialska-major-breakthroughs-unsupnmt,
author = {Biesialska, Magdalena},
title = {Major Breakthroughs in... Unsupervised Neural Machine Translation (V)},
year = {2021},
howpublished = {\url{https://mt.cs.upc.edu/2021/03/08/major-breakthroughs-in-unsupervised-neural-machine-translation-v/}},
}