by Marta R. Costa-jussà, Carlos Escolano, Gerard I. Gállego
Multilingual Neural Machine Translation is the task that allows for translation among several pairs of languages. This task has progressed from a few pairs of languages to massively and efficiently dealing with hundreds of them. While there have been many publications in recent years that have helped towards this direction, here we select what we consider key and most impactful works on the area.
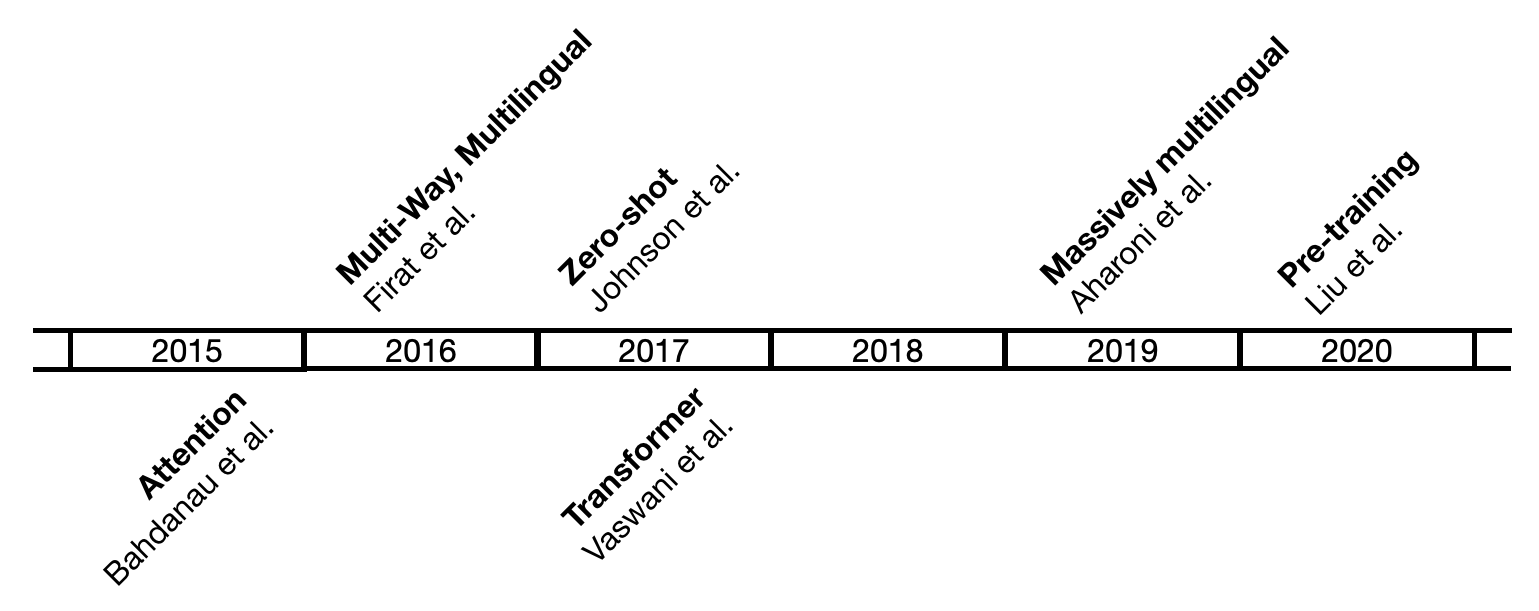
Among the most popular machine translation approaches, there are the rule-based, the statistical and the neural machine translation. Multilingual machine translation within the rule-based and statistical systems has been approached either from a pairwise, pivot, or interlingual approach. While pairwise approach requires a quadratic number of translation systems, pivot and interlingual had the advantage of having a linear dependency with languages. With the appearance of neural machine translation, new opportunities such as transfer learning, zero-shot, massive and pre-trained models have arisen. Multilingual approaches have evolved jointly with neural machine translation, which started with recurrent neural networks with attention (Bahdanau et al., 2015) and moved to the current Transformer architecture (Vaswani et al., 2017).
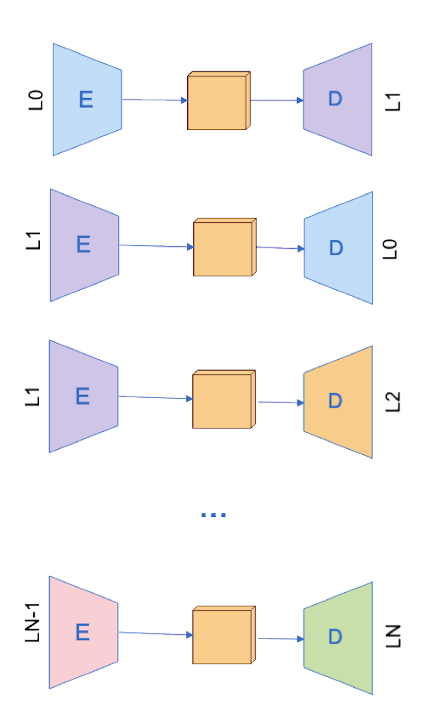
This research direction is based on the idea that translation from some language pairs can help learn others’. Somehow, this idea is inspired by previous multi-source approaches, where ambiguities by some languages may be solved by other ones. It has been addressed as an interpolation of conditional language models within the statistical paradigm (Och & Ney, 2001). More recently, within the neural approach, it has been addressed by modifying the attention layer with two context vectors (Zoph & Knight, 2016). A step forward is, what we were mentioning, the case of using multiple bilingual parallel corpora, for example, to improve the quality of low-resourced languages given the high-resourced ones. One of the first works to explore this path has been proposed by Firat et al. (2016a), which had N encoders and N decoders and a shared attention mechanism between all encoders and decoders. Both multi-source and multi-way ideas can be combined by computing the average of context vectors (e.g. early or late averaging).

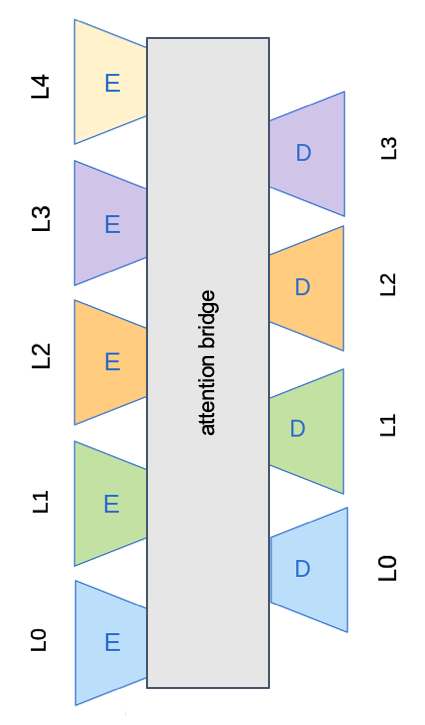
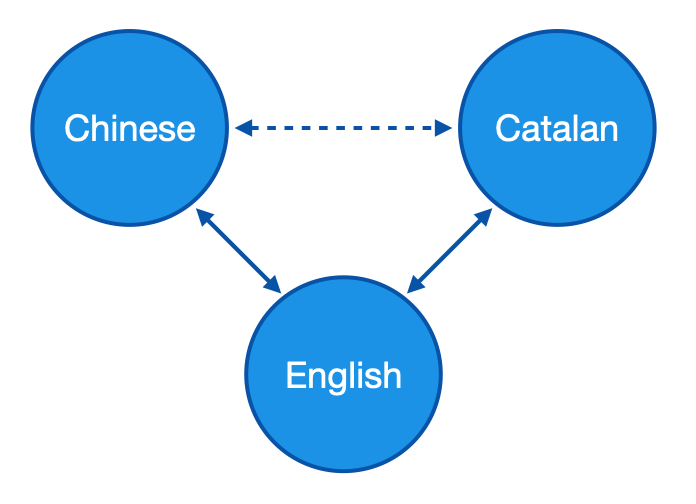
One of the limitations of this first approach was that it could not directly perform zero-shot translation (e.g. to translate Chinese-Catalan without being explicitly trained for it, after being trained with Chinese-English and English-Catalan). An alternative proposed by the same authors (Firat et al., 2016b) was to perform back-translation and fine-tune the shared attention layer with the new pseudo-parallel corpus. More recent approaches have also proposed new shared modules based on multi-head attention (Zhu et al., 2020) or even no sharing modules at all (Escolano et al., 2020), in order to achieve zero-shot translation.
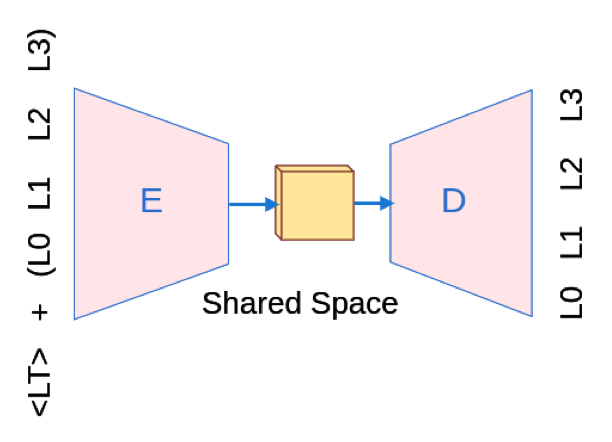
The first zero-shot without any parallel data (nor pseudo-parallel corpus) arrived with the idea of building one shared encoder-decoder instead of N encoders and N decoders. Basically, Johnson et al. (2017) proposed to learn a single function parameterized by the desired output language, where the implementation consisted of adding a token indicating the desired output language to input. This system improves by a higher amount over pairwise systems in many-to-one than in one-to-many. It may be explained because the decoder model can learn useful generalizations in the former case and not in the latter. Even in many-to-many, this system performs better when translating into English, since the system is trained exclusively with pairs from or to English (English-centric). This system is especially interesting to solve the code-switching in the input language. Moreover, the paper came with the hypothesis that this system could build translation upon an interlingua. Since the trained encoder and decoder share all the parameters, the authors showed a visualization of the sentences’ intermediate representation in all N languages. They found out that sentences meaning the same thing in several languages tended to be close in this representation.

After achieving zero-shot, one natural step forward was to extend the shared encoder-decoder architecture to deal with a massive number of language pairs. The model has been extended to 103 language pairs (Aharoni et al., 2019), reaching 80 billion trainable parameters. While the model has been deeply studied in several directions (depth, language combinations…), it is worth mentioning the importance of rebalancing data. When keeping the original amount of data, low-resourced languages performance in multilingual baselines drop by a huge amount compared to the bilingual baseline. However, there is the contrary effect when doing over-sampling. In both cases, high-resourced language performance is still lower. These effects are accentuated in the same direction when increasing the number of languages.

Among the remaining challenges of this model, there was the problem of adding unseen languages to the model, which is allowed by default in other multilingual architectures (Escolano et al., 2020).
This challenge of adding new languages without retraining has been solved by influencing the research line of multilingual translation with the tremendous success of unsupervised models. Since the former boosts low-resource languages translation quality, and the latter can impressively model language. Pretrained models take advantage of using non-labelled data. Lewis et al. (2020), proposed the BART encoder-decoder model that combined the best of both encoder (BERT models) and decoder (GPT models) worlds. This BART has been multilingually extended in (Liu et al., 2020) by simply training the model in several languages simultaneously and showing that fine-tuning on downstream MT tasks dramatically improves the translation quality. Tang et al. (2020) showed that finetuning can be done on many directions at the same time, allowing for multilingual finetuning and, more importantly, this multilingual finetuning can be extended to new languages without retraining from scratch.

While this post is just a small selection of papers, each of these papers contributed with a revolutionary idea to multilingual machine translation, making one step towards the universal machine translation system. Needless to say that we can not have universal translation without multimodality to take into account non-written languages, which connects us to the speech translation post within this series.
-
Aharoni, R., Johnson, M., & Firat, O. (2019). Massively Multilingual Neural Machine Translation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (pp. 3874–3884). Association for Computational Linguistics.
-
Bahdanau, D., and Cho, K., & Bengio, Y., (2015). Neural Machine Translation by Jointly Learning to Align and Translate. In 3rd International Conference on Learning Representations, Conference Track Proceedings.
-
Escolano, C., Costa-jussà, M.R, Fonollosa, J.A.R, Artetxe, M. (2020) Multilingual Machine Translation: Closing the Gap between Shared and Language-specific Encoder-Decoders 16th conference of the European Chapter of the Association for Computational Linguistics (EACL), Online
-
Firat, O., Cho, K., & Bengio, Y. (2016a). Multi-Way, Multilingual Neural Machine Translation with a Shared Attention Mechanism. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 866–875). Association for Computational Linguistics.
-
Firat, O., Sankaran, B., Al-Onaizan, Y., Yarman. F.T., Cho, K., (2016b). Zero-resource translation with multilingual neural machine translation. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics.
-
Johnson, M., Schuster, M., Le, Q., Krikun, M., Wu, Y., Chen, Z., Thorat, N., Viégas, F., Wattenberg, M., Corrado, G., Hughes, M., & Dean, J. (2017). Google's Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation Transactions of the Association for Computational Linguistics, 5, 339–351.
-
Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., Stoyanov, V., & Zettlemoyer, L. (2020). BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (pp. 7871–7880). Association for Computational Linguistics.
-
Liu, Y., Gu, J., Goyal, N., Li, X., Edunov, S., Ghazvininejad, M., Lewis, M., & Zettlemoyer, L. (2020). Multilingual Denoising Pre-training for Neural Machine Translation.
-
Och, F. J., & Ney, H. (2001). Statistical multi-source translation. In Proceedings of MT Summit (Vol. 8, pp. 253-258).
-
Tang, Y., Tran, C., Li, X., Chen, P., Goyal, N., Chaudhary, V., Gu, J., & Fan, A. (2020). Multilingual Translation with Extensible Multilingual Pretraining and Finetuning.
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A., Kaiser, L., & Polosukhin, I. (2017). Attention is All you Need. In Advances in Neural Information Processing Systems (pp. 5998–6008).
-
Zhu, C., Yu, H., Cheng, S., & Luo, W. (2020). Language-aware Interlingua for Multilingual Neural Machine Translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (pp. 1650–1655). Association for Computational Linguistics.
-
Zoph, B., & Knight, K. (2016). Multi-Source Neural Translation. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 30–34). Association for Computational Linguistics.
@misc{costajussa-major-breakthroughs-multinmt,
author = {Costa-jussà, Marta R. and Escolano, Carlos and Gállego, Gerard I.},
title = {Major Breakthroughs in... Multilingual Neural Machine Translation (II)},
year = {2021},
howpublished = {\url{https://mt.cs.upc.edu/2021/02/08/major-breakthroughs-in-multilingual-neural-machine-translation-ii/}},
}